Failures and errors happen frequently. A part breaks, an instruction is misunderstood, a rodent chews through a power cord. The issue gets noticed, we respond to correct it, we clean up any impacts, and we’re back in business.
Occasionally, a catastrophic loss occurs. A plane crashes, a patient dies during an operation, an attacker installs ransomware on the network. We often look for a single cause or freak occurrence to explain the incident. Rarely, if ever, are these accurate.
The vast majority of catastrophes are created by a series of factors that line up in just the wrong way, allowing seemingly-small details to add up to a major incident.
The Swiss cheese model is a great way to visualize this and is fully compatible with systems thinking. Understanding it will help you design systems which are more resilient to failures, errors, and even security threats.
Holy cheese
© Davidmack, used under a CC BY-SA 3.0 license.
{kind=link}
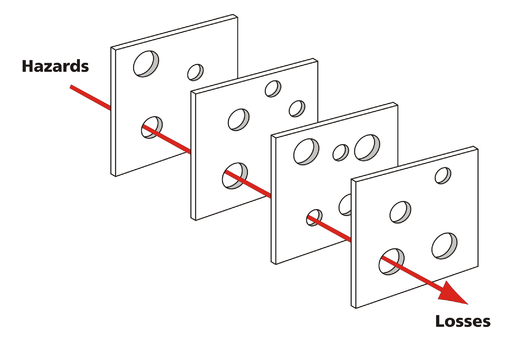
The Swiss Cheese Model was created by Dr. James Reason, a highly regarded expert in the field of aviation safety and human error. In this model, hazards are on one side, losses are on another, and in between are slices of Swiss cheese.
Each slice is a line of defense, something that can catch or prevent a hazard from becoming a catastrophic loss. This could be anything: backup components, monitoring devices, damage control systems, personnel training, organizational policies, etc.
Of course, Swiss cheese is famous for its holes. In the model, each hole is a gap in that layer that allows the hazard condition to progress. A hole could be anything: a broken monitoring device or backup system, an outdated regulation or policy, a misunderstanding between a pilot and air traffic control, a receptionist vulnerable to social engineering, a culture of ‘not my job’.
If you stack a bunch of random slices of Swiss, the holes don’t usually line up all the way through. A failure in one aspect of the system isn’t catastrophic because other aspects of the system will catch it. This is a “defense in depth” strategy; many layers means many opportunities to prevent a small issue from becoming a major issue.
As shown in the diagram, sometimes the holes do line up. This is the trajectory of an accident, allowing an issue to propagate all the way through each layer until the catastrophic loss.

© Frank Kovalchek, used under a CC BY 2.0 license
A great example is UPS Flight 6, which crashed in Dubai in 2010. A fire broke out on board, started by lithium ion batteries which were being improperly shipped. Other planes, including UPS planes, have experienced similar fires but were able to land safely. This fire had to proceed through many layers before the crash happened:
- hazardous cargo policy — failed to properly identify the batteries and control where they were loaded in the plane
- smoke detection system — inhibited because rain covers on the shipping pallets contained the smoke until the fire was very large
- fire suppression system — not intended for the type of fire caused by batteries, thus less effective
- flight control systems — unable to withstand the heat and made controlling the plane increasingly difficult
- air conditioner unit failed — apparently unrelated to the fire, allowed the cockpit to fill with smoke
- cockpit checklists and crew training — didn’t have sufficient guidance for this type of situation, leading the crew to make several mistakes which exacerbated the situation
- pilot’s oxygen mask was damaged by the heat — he became incapacitated and likely died while still in the air
- copilot oxygen mask — he had on a mixed-atmosphere setting instead of 100% oxygen, allowing some smoke into his mask and reducing his effectiveness
- air traffic control wasn’t monitoring the emergency radio frequency — copilot tried to use this (international-standard) frequency, but air traffic controllers were not; he couldn’t find the airport without directions from the controllers
Ultimately, the flight control systems failed completely and the copilot could no longer control the aircraft. As you can see, this incident could have ended very differently if any single one of those nine layers did not allow the accident to progress1.
Applying the model in design
This model is most often used to describe accidents after-the-fact. But it’s just as applicable for describing the resiliency of the system during the design phase, where applying it can have the greatest impact on the safety and security of the system.
Add layers deliberately and with care
The layers of cheese in the model suggest that the easy solution to many holes is to add more layers of cheese. Another inspection step, component redundancy, a review gate, etc.
This is a defense-in-depth strategy and it’s essential for the first few layers. However, it quickly becomes onerous and costly. It can also backfire by providing a false sense of security (‘I don’t have to catch 100% of problems because the next step will’).
Before adding a slice, carefully analyze the system to determine if there may be a better way to address the concern.
Fill the holes
Most often, the best solution is to minimize the holes in each layer by making them more robust or to replace a layer with one that better addresses all of the risks.
An easy example might be the copilot’s oxygen mask setting from the UPS example above. The copilot had chosen a setting which varied the amount of oxygen based on altitude. In one sense, this setting makes sense; at a lower altitude the need for supplemental oxygen is lower. In another sense, there’s no risk in providing too much oxygen, so why not provide a simpler system which only delivers 100% oxygen and has less risk of error?
The best designs add minimal friction while providing value to the users. For example, a maintenance system which pre-fills documentation when the user scans a part. The user prefers it because it simplifies their job, documentation is more complete/accurate, and the system can automatically double-check that the part is compatible.
This is always going to be easiest to accomplish during initial design rather than added after the fact. Software engineering has made a big step forward in this regard with DevSecOps, baking security right in rather than trying (usually with little success) to force it on the system later. Resiliency should be incorporated into every step of an engineering project.
Analyze and accept risk
Finally, there’s never going to be a 100% safe and secure system. We must quantify the risks as best as possible, control them as much as practicable, and eventually accept the residual risk.
How have you applied the Swiss cheese model in your work? Do you have any criticisms of it or perhaps an alternative perspective? Share your thoughts in the comments.
Footnotes:
- On the other hand, imagine how close you may have been to disaster throughout your life if not for 1-2 layers of cheese.